Теоретичні моделі вживаються далеко не в усіх розділах комп’ютерної науки. Скажімо, ніхто ніколи не чув за теорію, яка лежить в основі текстових процесорів чи електронної пошти. Ніхто не журиться питанням, чи операції “вирізати / скопіювати / вставити” утворюють повний набір операцій над текстом, і тим не менше тексти пишуться, текстові процесори вдосконалюються, виходячи з чисто практичних міркувань.
Чому ж не можна обійтись без теоретичних викладок в царині баз даних (БД)? Це пов’язано насамперед з неймовірною складністю процесів визначення та обробки структуризованих і формалізованих даних за допомогою комп’ютерів. Якщо досконалий текстовий процесор можна уподібнити автомобілю, то будь-яка база даних в порівнянні з ним - це літак. Автомобіль можна збудувати, виходячи з міркувань здорового глузду та практичних потреб, але спроба будувати літак без аеродинамічних розрахунків неодмінно буде невдалою.
По-друге, кожна база даних, по самій суті справи, це система колективного використання. Ролі проектувальника, адміністратора, редактора-наповнювача та користувача кінцевої інформації для однієї бази є цілком різними, і взаємодія між ними може бути успішною тільки в тому випадку, коли всі учасники процесу будуть розуміти функції всіх частин бази однаково.
Отже, формалізація опису баз даних та розробка теоретичних моделей для них випливають з необхідності точно пояснити комп’ютерам та іншим людям, чим має бути та чи інша база даних. Найбільшим досягненням на цьому шляху є реляційна теорія баз даних, розвиток якої започатковано Е. Коддом. В цій теорії база даних розглядається як набір незалежних двовимірних таблиць. Над множинами рядків, вибраних з таблиць, визначаються теоретико-множинні операції (об’єднання, перетин і т.д.), визначається синтаксис і семантика операцій об’єднання таблиць. Основна ідея цієї теорії полягає в тому, що більшість операцій над таблицями призводять до створення нових таблиць, які можуть використовуватись в подальшому нарівні з висхідними таблицями.
Наявність реляційної теорії вважається серйозною перевагою промислово підтримуваних систем управління базами даних, які скорочено умовно називаються “реляційними”. Всі вони, в тому чи іншому ступеню, використовують мову структурних запитів (structured query language, SQL) в якості формальної мови опису даних та маніпулювання даними. Але попри популярність терміну “реляційний” в назвах і рекламних оголошеннях поширених СУБД, з правдивою реляційністю у цих продуктів є великі проблеми. Навіть якщо не звертати уваги на 333 ознаки справді реляційної СУБД, сформульовані Коддом, досить сказати, що жодна з “реляційних” СУБД не підтримує такої важливої операції реляційної алгебри, як перетин множин записів; нема такої операції і в стандарті SQL (в SQL визначено операцію об’єднання множин записів (оператор SELECT … UNION), яка підтримується в більшості продуктів).
Тому твердження, що “реляційні” програмні продукти є втіленням теоретичної моделі, є певним перебільшенням; правильніше сказати, що ці продукти розвивались під впливом реляційної теорії.
Ми хочемо запропонувати увазі читачів новий варіант теорії баз даних - об’єктну модель. Ця теоретична модель буде зручною для реалізації - хоча б тому, що реалізувати об’єктну модель у відповідності до теоретичних накреслень простіше, ніж всупереч ним.
Об’єкти
Об’єкт - це структура даних та методів їх обробки, які розглядаються як єдине ціле. Основними рисами об’єктного підходу в інформатиці, як відомо, виступають :
-
замкненість (incapsulation). В силу цієї властивості об’єкт захищає свої дані та методи від стороннього втручання, визначаючи правила звертання до даних та методів (interface). Наслідком замкненості є принцип актуалізму : допустимими (або примітивними) є тільки такі операції над об’єктами, які не вимагають зміни стану інших об’єктів. Операція, яка вимагає зміни стану одразу кількох об’єктів, не є примітивною. Її треба захищати об’єктною трансакцією;
-
типізація. В силу цієї властивості про кожен об’єкт можна сказати, якого він є типу (або до якого класу він належить). Ми вживаємо терміни “тип” і “клас” щодо об’єктів як рівнозначні;
-
наслідування (inheritance). Дана властивість встановлює ієрархічні відносини між класами об’єктів, в силу якої клас-нащадок успадковує всю поведінку класу-предка, додаючи до неї в міру потреби щось нове;
-
поліморфізм (polymorphism). Дана властивість означає, що ми можемо розглядати об’єкти підкласів як об’єкти суперкласу без будь-яких обмежень;
-
постійність (persistency). Дана властивість означає, що об’єкти зберігаються в базі даних і існують в ній постійно, незалежно від того, чи виконується в даний момент програма, яка з ними працює;
-
послідовність (consistency). Ця властивість, яка часто не вважається такою ж істотною, як попередні, означає, що у правдивому об’єктному проекті всі істотні частини мусять виступати як об’єкти, що уніфікує підходи до їх розробки і полегшує розуміння.
Отже, в основі об’єктної моделі лежать класи об’єктів. Клас складається з декларації класу (declaration) та множини екземплярів класу (instances). Декларація класу визначає, що особливого має саме даний клас (попри те, що він успадкував від суперкласів). Екземпляри класу слугують власне для зберігання інформації про об’єкти предметної області.
Кожен клас характеризується певним набором властивостей (properties). Властивості описуються в декларації класу і характеризують змістовне навантаження екземплярів даного класу. Можна вважати, що кожен екземпляр - це унікальний набір певних властивостей.
Декларацію класу можна розглядати як набір властивостей таких типів:
- атрибути (attributes). Структури даних, які зберігають конкретні елементи інформації для кожного екземпляра об’єкту. Атрибути є основним наповненням об’єктів, які зберігаються в базі даних;
- вирази (expressions). Псевдоатрибути, значення яких вираховується за значеннями атрибутів та інших виразів. Вони відрізняються від атрибутів тим, що їх значення не зберігаються в базі даних;
- індекси (indices). Атрибути або вирази, з яких формуються структури швидкого доступу до об’єктів в базі даних. За допомогою індексу ми можемо дізнатись про значення даного атрибуту, не відкриваючи сам об’єкт;
- правила (rules). Логічні вирази (предикати), які визначають допустимість значень атрибутів чи їх комбінацій. Об’єкт можна зберегти в базі даних тільки якщо всі його правила виконуються (є істинними);
- види (views). Набір атрибутів та виразів, розташованих у певній логічній послідовності. Він створюється саме заради упорядкування елементів даних для користувача. Сама декларація класу може не визначати ані послідовності збереження атрибутів в тілі екземпляру, ані порядку їх пред’явлення користувачеві;
- методи (methods). Процедури обробки даних, які визначають динамічну поведінку об’єктів. Методи визначені в класі об’єктів і є однаковими для всіх екземплярів класу;
- події (events). Ситуації, що виникають під час виконання тих чи інших методів об’єктів;
- обробники, або реактори (handlers). Процедури, які обробляють події, або визначають реакцію на події (тому реактори). На відміну від методів, обробники є частинами екземплярів об’єктів, вони призначаються (або не призначаються) для кожного об’єкта зокрема. Завдяки обробникам різні екземпляри одного класу можуть мати різну поведінку.
Про три останні групи властивостей ми в даному повідомленні говорити практично не будемо; ми зосередимо увагу на об’єктах бази даних як на статичних структурах даних.
Постійні об’єкти
В основу об’єктної бази даних покладено постійний об’єкт (persistent object, ПерсОб’єкт). Це абстрактний системний клас, який є кореневим (ultimate ancestor) для всіх інших об’єктів.
Термін абстрактний означає, що екземпляри даного класу не створюються - цей клас запроваджено тільки як основу для більш спеціалізованих підкласів.
Термін системний означає, що даний клас реалізовано в самій об’єктній СУБД, на відміну від проблемних класів, які створюються користувачем для моделювання предметної області. Об’єктна СУБД мусить дати користувачеві весь необхідний інструментарій для створення проблемних класів.
Цей клас визначає три властивості:
- ідентифікатор (скорочено ід) - атрибут, який визначає унікальність кожного екземпляра в базі даних; знаючи ід, ми завжди можемо знайти потрібний об’єкт (або переконатись у його відсутності). Тип даних для цього атрибута визначається реалізацією;
- логічне ім’я - віртуальний вираз рядкового типу, який допомагає людині розпізнати об’єкт; віртуальність означає, що класи-нащадки можуть визначати власні вирази для логічного імені, можливо, з урахуванням значення успадкованого виразу;
- користувачі є виразом з типом даних “множина об’єктів” (див. далі); ця множина містить усі об’єкти, які посилаються на даний об’єкт (тобто використовують даний об’єкт).
В цьому класі повинна бути реалізована основна поведінка об’єктів бази даних, тобто методи:
- створення нового об’єкту. Основна особливість семантики цього методу полягає в тому, що клас нового об’єкту визначається саме під час створення і потім не може бути змінений ні за яких обставин. Таким чином, наша об’єктна модель підтримує тільки статичну типізацію і не дозволяє динамічно змінювати клас об’єкту;
- ретипізація. Як виняток з попереднього правила можна допустити тільки перетворення екземпляра суперкласу на екземпляр одного з його підкласів. При цьому новоутворений екземпляр підкласу має визначеними тільки ті атрибути, які він успадкував від суперкласу. Такий екземпляр може виявитись “нежиттєздатним” через порушення правил підкласу;
- знищення існуючого об’єкту. Цей метод може бути виконаний лише тоді, коли немає ніяких інших об’єктів, які посилаються на даний об’єкт (або використовують його, що ми вживаємо як синонім);
- запис об’єкту в базу даних. Цей метод перевіряє всі правила класу і в разі їх задоволення записує об’єкт, підтримуючи при цьому оновлення індексів об’єкту.
- читання об’єкту з бази даних (або відкриття об’єкту, що ми вживаємо як синонім). Цей метод завантажує об’єкт з бази даних в оперативну пам’ять і забезпечує доступ до всіх атрибутів об’єкту.
В силу принципа замкненості кожен об’єкт читається або записується повністю; тому операція зміни значення атрибуту, дуже характерна для табличних баз даних, не є елементарною в об’єктній базі даних. Така операція оновлення взагалі не належить до функцій бази даних - її має виконувати програма обробки бази даних, яка одержує від БД завантажений об’єкт, змінює його і передає в БД для збереження.
З кожним із цих методів може бути зв’язана пара подій (ПередВиконаннямМетоду / ПісляВиконанняМетоду); додаткові події можуть бути зв’язані, скажімо, з обчисленням значень виразів або з виявленням порушення правил класу.
Метаінформація
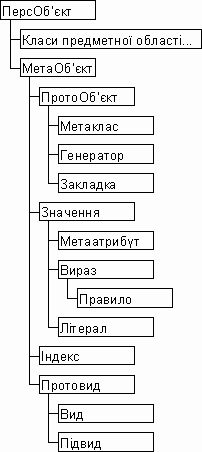
Метаінформація - це інформація про структуру іншої інформації. Оскільки в будь-якій базі даних зберігається структурована інформація, кожна БД у той чи інший спосіб визначає метаінформацію, яка необхідна для кодування/декодування та осмислення записів в БД. В силу послідовності об’єктної моделі ми представляємо метаінформацію у вигляді екземплярів спеціалізованих класів. В пропонованій моделі абстрактним носієм метаінформації є МетаОб’єкт - абстрактний системний клас, який є нащадком ПерсОб’єкту (рис. 1).
Кожен екземпляр метаоб’єкта має по одному екземпляру таких атрибутів:
- ім’я з типом даних “рядок” є символьним ідентифікатором, під яким екземпляр відомий у системі. Його семантика близька до логічного імені, тому цей атрибут є непоганим кандидатом на звання логічного імені;
- власник з типом даних “вказівник на МетаОб’єкт”. За допомогою цього атрибута екземпляри-метаоб’єкти можна зв’язати у дерево (подбавши про заборону циклічних посилань типу Х.Власник := Y; Y.Власник := X). Семантика цього зв’язку на рівні метаоб’єкту не визначається - це роблять нащадки метаоб’єкту;
- коментар з типом даних “рядок”, який містить пояснення щодо призначення даного екземпляру.
Тепер ми можемо побачити, звідки беруться користувачі екземплярів : зокрема, для кожного екземпляра метаоб’єкту користувачами є інші екземпляри метаоб’єкту, для яких “Власник” вказує на даний екземпляр.
Таким чином, основне призначення МетаОб’єкту - надати нащадкам механізм зв’язування екземплярів у дерево.
ПротоОб’єкт - абстрактний системний клас, успадкований від МетаОб’єкту, який визначає дві множинні властивості :
- вирази - множина екземплярів класу Вираз;
- види - множина екземплярів класу ПротоВид.
Вирази призначено для представлення інформації про екземпляр, основаної на значеннях його атрибутів, наприклад, для розрахунку площі прямокутника за значеннями довжини та ширини. Види призначено для управління видимістю та порядком слідування значень (атрибутів / виразів) під час пред’явлення інформації.
В ПротоОб’єкті реалізовано також три методи:
- абстрактний віртуальний метод Вибрати (аналог оператора SQL SELECT). Цей метод повертає множину екземплярів, пов’язану з даним протооб’єктом. Детальну семантику цього метода визначають нащадки ПротоОб’єкту. Як і у випадку з ПерсОб’єктом, з цим методом можна зв’язати дві події (ПередВибиранням / ПісляВибирання);
- ОбчислитиДекларативнийКлас, ОбчислитиФактичнийКлас - результатом виконання методів є клас, який є спільним суперкласом для множини об’єктів, що її повертає метод “Вибрати”. Різниця між ними та, що декларативний клас множини обчислюється тільки на підставі опису способу формування множини (без звертання до екземплярів класів); цей метод є абстрактним і віртуальним. Фактичний клас обчислюється шляхом аналізу множини об’єктів, створеної методом “Вибрати”.
Таким чином, основне призначення ПротоОб’єкту - надати нащадкам механізм формування множин екземплярів.
Від ПротоОб’єкту утворюються два системних класи, які не є абстрактними - Генератор та МетаКлас (третього нащадка - Закладку - розглянемо пізніше). Розглянемо спочатку простіший клас - Генератор. Він має один специфічний атрибут - генеруючий вираз - синтаксис якого буде розглянуто нижче. Генеруючий вираз використовується під час виклику методу “Вибрати” для генератора, і результат обчислення цього виразу є результатом виклику методу. Вказівник “Власник” для генератора може вказувати на інший генератор; в такому випадку він означає відношення використання (даний генератор може в своєму генеруючому виразі посилатись на вираз генератора-власника). Метод ОбчислитиДекларативнийКлас для генератора аналізує генеруючий вираз і обчислює спільний суперклас для всіх операндів.
Таким чином, основне призначення Генератора - створити механізм виконання операцій над множинами об’єктів.
МетаКлас є центральним в ієрархії системних класів. Він визначає три множинних властивості :
- множину атрибутів;
- множину індексів;
- множину правил.
Семантика цих властивостей визначається семантикою системних класів Метаатрибут, Вираз, Індекс, Правило.
Атрибут “Власник” для кожного екземпляру МетаКласу вказує на інший екземпляр МетаКласу, який виступає як суперклас. Таким чином, цей атрибут відбиває ієрархію спадковості для класів предметної області, які є екземплярами МетаКласу.
Метод “Вибрати” повертає множину всіх екземплярів задекларованого предметного класу разом з усіма екземплярами усіх його підкласів. Додатковий метод ВибратиПрямийКлас вибирає тільки екземпляри задекларованого класу (без екземплярів підкласів). Метод ОбчислитиДекларативнийКлас повертає як результат сам клас.
Основна відмінність МетаКласу полягає в тому, що на основі його екземплярів - класів предметної області - створюються екземпляри самої предметної області. Інакше кажучи, екземпляри МетаКласу є метаоб’єктами, в той час як екземпляри інших системних класів представляють тільки самих себе і не є зразками для утворення інших екземплярів. Важливо розуміти, що самі класи предметної області успадковуються від ПерсОб’єкта (тобто атрибут “Власник” для декларації проблемного класу вказує на ПерсОб’єкт або на іншу декларацію проблемного класу).
Таким чином, основне призначення МетаКласу - забезпечити механізм ієрархічного успадкування для класів предметної області.
Значення - абстрактний системний клас без спеціальних властивостей, який є основою для конкретних класів МетаАтрибут та Вираз. Атрибут “Власник” для нього вказує на екземпляр МетаКласу, якому належить даний екземпляр “Значення”, і виражає відношення використання.
МетаАтрибут є конкретним класом, екземпляри якого описують атрибути класів предметної області. Він має такі атрибути:
- обов’язковий - логічне значення; якщо воно є істинним, порожнє значення (null value) атрибута є неприпустимим;
- множинний - логічне значення; якщо воно є істинним, атрибут є векторним (може мати кілька екземплярів значення); якщо воно є ложним, атрибут є скалярним (містить не більше одного значення);
- тип даних атрибута та додаткові атрибути, специфічні для певного типу даних. Конкретна множина типів даних залежить від реалізації; найнеобхіднішими типами є рядки, числа, логічні значення та вказівники. Прикладами додаткових атрибутів можуть бути формат виводу для чисел або клас об’єкта-цілі для вказівника (ми пропонуємо задавати цей клас, щоб вказівники були типізованими).
Вираз - конкретний клас, призначений для розрахунку значень за правилами, які записані у його атрибуті Формула. Формула складається із значень (атрибутів / виразів / літералів), поєднаних символами операцій. Набір операцій залежить від набору типів даних в об’єктній СУБД; детальний опис синтаксису формул належить скоріше до реалізації.
Літерал - конкретний клас, призначений для представлення сталих значень у формулах. Він визначає один атрибут * *ЛітеральнеЗначення**, тип даних якого - екземпляр атрибута. Тип даних літерала визначається типом даних цього екземпляра; тобто літерал є поліморфним, здатним представляти значення довільного типу.
Таким чином, всі підкласи класу Значення призначені для представлення одного примітивного значення якогось типу; різниця між ними полягає в тому, що атрибут містить безпосереднє значення, яке може бути різним для різних екземплярів об’єктів, літерал містить безпосереднє значення, однакове для всіх екземплярів об’єктів, а вираз містить правило розрахунку значення.
Правило є нащадком класу Вираз. Задана в ньому формула має повертати значення логічного типу. Правило дозволяє або забороняє дію, в контексті якої воно виконується. Наприклад, правило класу виконується в контексті методу збереження об’єкту. Якщо значення правила істинне, дія виконується; якщо воно ложне, виникає помилка і дія скасовується. Таким чином, за допомогою правил класу можна перевіряти умови, які залежать від значень одразу кількох атрибутів.
Якщо в одному контексті визначено кілька правил, всі вони мають виконуватись одночасно; порядок їх обчислення задається реалізацією; правила не повинні покладатись на припущення, що вони завжди будуть обчислюватись у певній послідовності. Задаючи набір правил, треба дбати про їхню сумісність. Якщо правило А вимагає, щоб атрибут Х був менше 5, а правило В - щоб атрибут Х був більше 10, то під управлінням такої множини правил не можна буде виконати ніякої дії. Автоматичне доведення сумісності або несумісності множини правил - це окрема алгоритмічна проблема, в яку ми не будемо заглиблюватись.
В силу принципу актуалізму запровадження нових правил класу не впливає на раніше записані екземпляри класу - навіть якщо вони не задовольняють новому правилу. Такі екземпляри можуть зберігатись і використовуватись необмежено довго - аж до моменту, коли екземпляр буде змінено і відбудеться спроба запису його в базу даних. Така особливість стану цілісності інформації відповідає об’єктному підходу та внутрішній логіці певних предметних областей (прикладом є відсутність зворотньої дії закону в юриспруденції).
Індекс - конкретний системний клас, призначений для організації логічного індексування об’єктів. Індексування об’єктів має на меті прискорення відбору та сортування екземплярів об’єктів на підставі найчастіше вживаних “Значень”, пов’язаних з об’єктами. Відбір екземплярів в об’єктній СУБД не є швидкою операцією : для того, щоб перевірити значення якогось атрибута, треба прочитати весь об’єкт. Індексування дозволяє дізнатись про значення атрибута, не відкриваючи самого об’єкта. Термін “логічне” в даному випадку означає, що ми розглядаємо індекс лише як спосіб упорядкування екземплярів, без огляду на фізичні структури даних, які його забезпечують.
Атрибут “Власник” для індексу вказує на метаклас, для якого визначено індекс. Індекс визначає векторний атрибут ІндексніЗначення, в якому перелічено якісь “Значення” (атрибути або вирази), властиві даному класу. В загальному випадку індекс є множинним, упорядкованим за величиною першого індексного значення, при рівній величині його - за величиною другого індексного значення і т.д. Найважливішим частинним випадком є одиничний індекс, збудований за одним індексним значенням.
ПротоВид - абстрактний системний клас, який є базою управління візуальним представленням об’єктів. Його атрибут “Власник” вказує на ПротоОб’єкт, представлення якого треба визначити. Для кожного Значення (атрибута або виразу), наявного у власнику, ПротоВид визначає його місце у послідовності Значень та правило видимості. Правило видимості застосовується під час пред’явлення даного Значення : Значення буде показано лише у випадку істинності правила. Набір Значень, які знаходяться під управлінням ПротоВиду, визначається ДекларативнимКласом для ПротоОб’єкта-власника ПротоВиду.
За допомогою таких гнучких засобів можливо створити на основі однієї сукупності екземплярів документи різної структури і вигляду. Наприклад, для класу “Людина” один вид може визначити послідовність атрибутів “Прізвище”, “Ім’я”, “По батькові”; другий вид - послідовність “Ім’я”, “По батькові”, “Прізвище”; третій вид - послідовність “Ім’я”, “Прізвище”, приховавши атрибут “По батькові”. Четвертий вид можна зробити на основі третього, але більш гнучким, скажімо, наказавши показувати атрибут “По батькові” лише в тому разі, коли він не є порожнім (перший і другий види в нашому прикладі показують цей атрибут незалежно від того, чи містить він якісь дані, чи ні). Таким чином, за допомогою правил видимості можна управляти видимістю значень на рівні окремого екземпляру.
ПротоВид може також визначати додаткові Вирази, відсутні у власника, але потрібні в контексті даного виду.
Вид є конкретним класом - нащадком ПротоВиду. Він володіє трьома додатковими властивостями :
- Фільтр є екземпляром Правила, яке визначає видимість екземпляра в цілому, безвідносно до видимості окремих Значень.
- ПорядокСортування є екземпляром Індексу, який визначає послідовність пред’явлення екземплярів;
- Атрибут ОбмеженняВводу є логічним значенням - аналогом опції SQL WITH CHECK OPTION.
Властивість ПорядокСортування застосовується перед відкриттям виду і не може бути змінена під час його використання ( тобто зміна порядку сортування рівнозначна відкриттю нового виду). Якщо ПорядокСортування співпадає з якимось логічним індексом, вживається цей логічний індекс; в інших випадках Вид мусть забезпечувати сортування власними силами.
Властивість Фільтр обчислюється в контексті операції Відкриття екземпляру : якщо правило дозволяє, екземпляр буде пред’явлено. Отже, визначений для виду фільтр не намагається проглянути множину екземплярів заздалегідь; замість того він чекає, поки надійде вимога показати той чи інший екземпляр.
Атрибут ОбмеженняВводу керує процесом збереження об’єктів, які додаються або редагуються під управлінням Виду. Якщо ця властивість істинна, набір правил класу доповнюється правилом фільтрування для Виду. Якщо об’єкт під управлінням такого набору правил можна зберегти в БД, то це є гарантією того, що він не “зникне з поля зору” і буде доступним через даний Вид.
Організований у такий спосіб Вид є мономорфним : кожен екземпляр об’єкту, незалежно від його конкретного класу, розглядається через призму поліморфізму як екземпляр ДекларативногоКласу для ПротоОб’єкта, який є власником виду. Завдяки конкретному класу Підвид можна організувати мудріший поліморфний вид. Для цього в класі Підвид визначено атрибут Супервид, який є вказівником на ПротоВид (тобто Вид або інший Підвид). Завдяки цьому атрибуту екземпляри Підвиду зв’язуються у дерево, в корені якого знаходиться екземпляр Виду (він визначає правила фільтрування та сортування для всього дерева).
Працює цей поліморфний вид у такий спосіб: якщо треба пред’явити екземпляр об’єкту такого класу, для якого визначено екземпляр Підвиду, застосовується Підвид; інакше ми піднімаємось по ланцюжку суперкласів до першого класу, для якого визначено Підвид або Вид, належний даному поліморфному виду.
З усіх цих системних об’єктів Значення з його підкласами, Метаклас та Індекс є об’єктами визначення даних, а об’єкти ПротоВид з підкласами, Генератор і Закладка - об’єктами маніпулювання даними. З них справді необхідними є МетаКлас та МетаАтрибут. Створивши дерево класів предметної області (тобто певну кількість екземплярів МетаКласу) і задавши їх атрибути (тобто створивши певну кількість екземплярів МетаАтрибуту), можна приступати до наповнення бази даних, тобто до створення екземплярів класів предметної області. Конкретна інформація про предметну область зберігається тільки в цих екземплярах. Важливо розуміти, що ці екземпляри не містять нічого, окрім значень атрибутів даного екземпляру. Усілякі інші дані, необхідні для розуміння та використання значень атрибутів, зберігаються у вигляді метаінформації.
Модель наслідування
Модель наслідування в пропонованій системі знаходиться під управлінням дерева класів. Як ми вже згадували при описі МетаКласу, кожна декларація класу має рівно один безпосередній суперклас, за винятком ПерсОб’єкту, який не має суперкласу і виступає пращуром (ultimate ancestor) усіх інших класів. Таким чином, множинна спадковість (можливість успадковувати клас від кількох суперкласів) не використовується.
В силу наслідування всі множинні властивості поповнюються в напрямку від суперкласу до підкласів, тобто для кожної множинної властивості всі елементи множини, доступні у суперкласі, є доступними також в усіх його підкласах, поруч з тим, що кожен підклас може додавати до цієї множини власні елементи. Таким чином, підклас наслідує множини атрибутів, виразів, індексів, правил та видів, визначених у суперкласі, і може розширювати ці множини.
Всі методи та події суперкласу також доступні в підкласах; але оскільки ми зосереджуємось на статичній моделі даних, нами не розглядається можливість створення в класах предметної області власних методів та подій.
В силу принципу послідовності об’єктної моделі всі описані вище системні класи (починаючи від ПерсОб’єкта) є екземплярами МетаКласу, для яких значення атрибута “Власник” (суперклас) показано на рис. 1; тому для них є чинними всі правила наслідування.
Множини об’єктів і закладки
МножинаОб’єктів - це невпорядкований набір екземплярів ПерсОб’єкта (тобто екземплярів будь-яких класів бази даних). В силу послідовності об’єктної моделі його теж слід вважати об’єктом, але цей об’єкт існує тільки в пам’яті комп’ютера і тому нема потреби успадковувати його від персистентного об’єкта.
Закладка - це персистентний образ множини об’єктів. В ієрархії системних об’єктів Закладка успадковується від ПротоОб’єкту, наслідуючи від нього ім’я та методи Вибрати і ОбчислитиДекларативнийКлас (цей останній метод завжди повертає ПерсОб’єкт, який є декларативним класом будь-якої закладки). Таким чином, закладка - це іменована множина об’єктів, яка зберігається в базі даних.
Кожен об’єкт може входити до множини не більше одного разу (в SQL такий режим забезпечується опцією DISTINCTROW). Отже, якщо додати до множини об’єкт, який у ній вже міститься, множина не зміниться. Важливо розуміти, що множина не є монопольним власником своїх об’єктів і належність об’єкту до однієї множини не заважає йому належати до іншої множини. Щоб точно зрозуміти цю особливість, можна вважати множину набором вказівників на об’єкти.
МножинаОб’єктів визначає два методи :
- Зберегти - утворює закладку з множини;
- Ітератор - виконує певну дію, задану як аргумент, над усіма елементами множини, причому порядок обходу множини не визначається (залежить від реалізації).
Сукупність множин об’єктів утворює алгебраїчне кільце відносно операцій “сума” та “перетин” :
- множина Х є сумою множин А та В, якщо будь-який об’єкт, що належить до А або до В, одночасно належить і до Х;
- множина Х є перетином множин А та В, якщо будь-який об’єкт, що належить одночасно і до А, і до В, одночасно належить до Х;
Визначимо також бінарну операцію “різниця”:
- множина Х є різницею множин А та В, якщо будь-який об’єкт, що належить до А і в той же час не належить до В, одночасно належить до Х.
До числа унарних операцій над множинами відносяться фільтрування, сортування, групування та упорядкування.
Результатом фільтрування множини А під управлінням предиката Р є така множина В, що для будь-якого об’єкту, який належить одночасно і до А, і до В, значення предиката є істинним. В табличних системах цю функцію виконує фраза WHERE оператора SELECT. Алгоритмічно фільтрування можна виразити таким чином :
В := []; {порожня множина}
А.Ітератор(якщо (Р) то В := В + [поточний об’єкт]);
Результатом сортування множини А під управлінням функції сортування F є частково або повністю відсортована множина. В табличних системах цю функцію виконує фраза ORDER BY оператора SELECT.
Функція сортування F(M1, M2) має повертати -1, якщо об’єкт M1 має передувати M2, 0 - якщо їхній відносний порядок неістотний, +1 - якщо M2 має передувати M1, спеціальне значення nil - якщо функція порівняння не може бути обчислена ( таке може трапитись, напиклад, якщо порівнюються значення якогось атрибуту і хоча б один з об’єктів не має цього атрибуту).
Множина А є повністю сортованою відносно F, якщо для будь-якої пари об’єктів M1, M2, що належать до множини А, значення функції не дорівнює nil. Якщо ж значення, для яких F = nil існують, множина є частково сортованою. Nil-значення можна вважати або меншим, або більшим за будь-яке реальне значення (це залежить від реалізації).
На повністю сортованій множині (або на сортованій частині частково сортованої множини) ітератор повинен обходити об’єкти в порядку їх сортування.
Результатом групування множини під управлінням набору функцій групування {G1 … GN} є частково або повністю згрупована множина. В табличних системах цю функцію виконує фраза GROUP BY оператора SELECT.
Для кожного об’єкту М з множини функція Gk(M) повертає якесь значення або nil. Всі об’єкти з однаковим значенням функції групування утворюють часткову множину або групу; об’єкти, для яких функція групування дає nil, утворюють залишкову групу.
Операція групування встановлює над множиною структуру дерева, коренем якого є сама множина, вершинами першого рівня - групи, утворені функцією G1, вершинами другого рівня - групи, утворені функцією G2 всередині груп першого рівня, і т.д.
Повністю згрупованою є множина, в якій немає жодної залишкової групи; формально це така множина, що для кожного її об’єкту значення усіх функцій групування є визначеним. По суті це множина, згрупована виключно на позитивних засадах, без залишкових груп, підстава для утворення яких є чисто негативною - неналежність об’єктів до жодної позитивної групи. Частково згрупована множина містить залишкові групи.
Важливим частинним випадком повністю згрупованої множини є класифікована множина, у якій групи утворені з екземплярів одного класу.
Складнішим варіантом групування є операція упорядкування множини. Упорядкованою будемо називати таку згруповану множину, для якої, по-перше, визначено порядок перебору груп; по-друге, об’єкти всередині груп відсортовано. Оскільки функція сортування вживається для порівняння об’єктів, належних до якоїсь однієї групи, вона може залежати від параметрів групування (тобто набору значень функцій групування, властивих даній групі) і таким чином для різних груп може бути встановлено різний порядок сортування.
Повністю впорядкована множина - це повністю згрупована множина, кожна група якої повністю відсортована; інакше множина є частково впорядкованою.
Множини і вказівники
Об’єкти, як ми вище визначили, можуть мати атрибути типу вказівник, які вказують на інші об’єкти. Ці вказівники відбивають зв’язки між частинами предметної області. Щоб скласти більш повне уявлення про даний об’єкт, необхідно розглянути об’єкти, які є значеннями атрибутів-вказівників; часто дуже корисним є розгляд об’єктів, які посилаються на даний об’єкт (користувачів даного об’єкту).
Тому важливим є процес об’єктного з’єднання (object joining) для збирання інформації, розділеної між кількома об’єктами. Внаслідок особливостей об’єктної архітектури предметної області необхідність з’єднання виникає набагато рідше, ніж при роботі з табличними архітектурами. Якщо в табличній базі даних розщеплення інформації між окремими таблицями ( нормалізація) і наступне з’єднання з кількох таблиць є постійною необхідністю, то в об’єктній базі даних порції інформації (атрибути), які відносяться до однієї частини предметної області (об’єкта), зберігаються всередині об’єкта і не потребують з’єднання. Можна сказати, що в об’єктній базі даних всі з’єднання табличного стилю, які мають реальний сенс, уже виконано.
Будемо називати зв’язком атрибут-вказівник або користувачів об’єкта. Властивість “Користувачі” не є атрибутом, але її роль щодо з’єднання така сама, як і в атрибута-вказівника.
Отже, розглянемо зв’язок А. Координаційною сферою множини Х відносно зв’язку А назвемо множину об’єктів, які є значенням зв’язку А для всіх елементів Х, разом із висхідною множиною Х. Операція побудови кооординаційної сфери є унарною операцією над множиною об’єктів, оскільки результатом її виконання є нова множина об’єктів. Алгоритм побудови координаційною сфери такий :
КС := X;
X.Ітератор(КС := КС + [поточний об’єкт].А);
Потужність координаційної сфери завжди більша за потужність висхідної множини. Неможливість побудови координаційної сфери свідчить про порушення цілісності бази даних, про наявність посилань на неіснуючі об’єкти. Перше застосування операції КоординаційнаСфера дає першу координаційну сферу; друге..N застосування - відповідно 2..N-у координаційну сферу. Оскільки число об’єктів в базі даних скінчене, рано чи пізно чергове застосування цієї операції не змінить множини:
КС(КСN) = КСN+1 є КСN
(в крайному разі ця сфера КСN може охопити всі об’єкти бази). Будемо називати таку множину замкненою відносно зв’язку А або А-галактикою. Взагалі таких галактик у базі даних можу бути декілька. Наприклад, в БД з генеалогії династії Рюриковичів та Гедиміновичів є галактиками відносно зв’язку “батько особи”.
По аналогії з поняттями координаційної сфери та галактики відносно одного зв’язку можна розглядати ці поняття відносно сукупності зв’язків {А1 … АК} або відносно повної сукупності усіх зв’язків, властивих множині Х. Побудова повної координаційної сфери є процесом з позитивним зворотнім зв’язком, оскільки включення до множини нових об’єктів може збільшити набір зв’язків множини, що відповідно розширяє наступну координаційну сферу.
Повна галактика найчастіше буде містити всі об’єкти бази даних. Адже якщо в БД є об’єкти, які не посилаються на інші об’єкти і не є предметами посилань, постає питання, що вони взагалі роблять у базі і яким частинам предметної області відповідають.
Операції над множинами об’єктів
Результатом усіх перелічених унарних та бінарних операцій над множинами об’єктів також є множина об’єктів, тому цей результат може виступати операндом іншої операції. Таким чином, можна будувати вирази множинного типу, які використовуються, зокрема, як значення атрибута ГенеруючийВираз для генераторів.
З використанням бекусівської нормальної форми синтаксис генеруючого виразу можна записати так:
| БінОперація : := + | - | * |
| Операнд : := ПротоОб’єкт.Вибрати | фільтрування(Операнд) | КоординаційнаСфера(Операнд) | (Операнд БінОперація Операнд) |
| ГенеруючийВираз : := Операнд | структурування(Операнд) |
Унарні операції пріорітетніші за бінарні. Серед унарних операцій над множинами операція фільтрування є найпріорітетнішою. Оскільки операція фільтрування комутативна
F1(F2(X)) є F2(F1(X))
то порядок виконання послідовних операцій фільтурвання може не визначитись.
Кожна з операцій структуризації (сортування, групування, упорядкування) встановлює нову структуру множини, скасовуючи попередню, якщо така існувала. Тому дія послідовності цих операцій рівносильна дії останньої операції :
S1(S2(…SN(X)…) є S1(X)
Слід пам’ятати, що коли стурктурована множина виступає операндом бінарної операції, її структура втрачається. Наприклад,
S1(X) + S2(Y) є X + Y
так що операції S1 і S2 можуть просто не виконуватись. Це враховано в синтаксисі, де операція структурування, якщо вона є, завжди є останньою (найбільш зовнішньою) операцією.
З числа бінарних операцій перетин є комутативною та асоциативною операцією, пріорітетнішою за суму та різницю, які мають рівний пріорітет. Операція суми є комутативною та асоциативною, а різниця не є ані комутативною, ані асоциативною, тому порядок обчислень у виразах з різницею є істотним. Вищенаведений синтаксис явно встановлює порядок виконання операцій, вимагаючи, щоб кожна бінарна операція була узята в круглі дужки.
Порівняння множин
Операції порівняння множин є бінарними операціями над множинами об’єктів, результатом яких є логічне значення.
Множина В менше або дорівнює множині А, якщо А + В є А.
Множина В менша за множину А, якщо А Ј В і при цьому А - В № [] (не є порожньою множиною).
Множини А та В є рівними, якщо А - В = [] або А * В = [].
Множини А та В не є рівними, якщо не має місце рівність.
Статистичні процедури над множинами
Ці статистичні процедури (в SQL вони звуться domain functions) є надзвичайно цікавими і корисними, якщо застосовуються для згрупованої (впорядкованої) множини об’єктів. Для незгрупованої множини вони діють так само, як для згрупованої множини, що складається з однієї групи.
Всі процедури повертають результат у вигляді дерева, структурно подібного до дерева груп, у вершинах якого записано результати процедури для окремої групи. Якщо група має підгрупи, результат дії процедури повинен бути таким, якби всі об’єкти підгруп безпосередньо належали даній групі. Таким чином, у множині з багаторівневим групуванням один виклик процедури одночасно обчислює інформацію для всіх рівнів групування.
Наприклад, найпростішою процедурою є підрахунок. Вона повертає число елементів у групі. В корені дерева, таким чином, знаходиться повне число елементів у множині, або потужність множини.
Аналогічно працюють процедури обчислення суми, середнього значення, середньоквадратичного відхилення. Аргументом цих процедур є числове Значення, для якого треба виконати обчислення. При потребі за допомогою цієї системи можна реалізувати складніші статистичні операції, такі як дисперсійний аналіз чи порівняння функцій розподілу.
Об’єкти прав доступу
Для регулювання доступу користувачів інформації до об’єктів бази даних можна спроектувати спеціальні системні об’єкти. Один ескізний варіант цих об’єктів гранично стисло описано нижче.
Перш за все, необхідно реалізувати об’єкт КористувачІнформації, задачами якого є ідентифікація користувача та зв’язування його з ГрупоюКористувачів.
ГрупаКористувачів володіє набором об’єктів ПравДоступу до класів. Кожен об’єкт ПравДоступу вказує на клас, для якого визначаються права, та набір логічних значень, які дозволяють або забороняють виконання певних методів для даного класу (наприклад, створення нових екземплярів, чи запису об’єктів, чи вибирання екземплярів).
Права доступу успадковуються, тобто поширюються на всі підкласи даного класу, якщо для якихось підкласів дана ГрупаКористувачів не визначає окремого об’єкта ПравДоступу. Таким чином, для задання прав адміністратора бази даних досить створити один об’єкт ПравДоступу, який визначає повний доступ для класу ПерсОб’єкт; аналогічно для реалізації права “тільки читання будь-якої інформації” треба створити один об’єкт ПравДоступу, який визначає право відкривати екземпляри для класу ПерсОб’єкт (зауважимо, що в табличній базі даних для реалізації такого права треба виконати процедуру надання права читання для кожної таблиці бази).
При необхідності об’єкти ГрупаКористувачів можна зв’язати в дерево для організації успадкування прав доступу від групи-господаря.
При такій системі права перевіряються під час виконання кожного із захищених методів. Тому якщо генератор створює множину з 10 об’єктів, для яких даний користувач має право читання для 8 і ніяких прав - для 2 об’єктів, то генерація множини пройде успішно, бо включення об’єкту до множини не передбачає відкриття об’єкту; але під час перегляду цієї множини користувач зможе побачити тільки ті 8 об’єктів, переглядати які він має право.
Обмін інформацією з табличними базами даних
Алгоритм перетворення об’єктної інформації у табличний вигляд можна використовувати для експорту даних або для підтримки таблично-орієнтованих інтерфейсів (таких як Open database connectivity). В загальних рисах він може виглядати так : для кожного класу об’єктів на підставі метаінформації створюється окрема таблиця, колонки якої відповідають скалярним атрибутам класу. Для кожного векторного атрибута створюється окрема таблиця, яка місить ід об’єкта як поле зв’язку з головною таблицею (тобто під час експорту відбувається автоматична нормалізація інформації).
Процедуру експорту можна реалізувати як метод МетаКласу.
Імпорт даних є значно складнішим, по-перше, через необхідність встановлювати відповідність між структурою імпортованої інформації та структурою класів об’єктної бази даних, по-друге, необхідно встановлювати відповідність між головною таблицею об’єктів та додатковими таблицями, які треба розглядати як джерело векторних атрибутів, по-третє, необхідно розпізнати, в яких ієрархічних відношеннях знаходяться між собою головні таблиці об’єктів (тобто яка таблиця містить об’єкти суперкласу, а яка - об’єкти підкласу). Це вимагає аналізу схеми даних у табличній базі даних і, можливо, додаткових алгоритмічних та інструментальних засобів.
В цілому обмін інформацією з табличними базами даних не є простою задачею, і головним чином через те, що набір засобів моделювання предметної області в табличних та об’єктних базах даних є кардинально різним.
Доступ до атрибутів в базі даних
Розглядаючи об’єкт Вираз, ми не зупинялись детально на синтаксисі формул, за якими обчислюється значення Виразу. Очевидно, що кожна формула може містити в якості операндів будь-які Значення, доступні у контексті ДекларативногоКласу того екземпляру ПротоОб’єкту, який є власником Виразу. При обчисленні Виразу в контексті певного екземпляра класа предметної області, формула використовує Значення, притаманні даному екземпляру (або безпосередні значення атрибутів, або значення обчислених виразів). Але формула може містити також Значення, притаманні іншим екземплярам (не тим, у контексті якого обчислюється Вираз).
Щоб видобути певне Значення для певного екземпляру, слід вживати такі операції :
- знаходження конкретного Значення для конкретного екземпляра, яка повертає величину Значення;
- індексація векторного атрибута, яка повертає скалярну величину певного компонента вектора;
- розіменування атрибута-вказівника, яка повертає об’єкт, що є значенням вказівника;
- типізація, яка дозволяє розглядати об’єкт суперкласу як об’єкт певного підкласу для того, щоб отримати доступ до специфічних Значень підкласу.
При будь-якій помилці ці операції повертають порожнє значення (nil) : наприклад, якщо даний об’єкт не має шуканого атрибута, або індекс вектора є невірним, або розіменовується атрибут, який не є вказівником. Операція типізації викликає помилку, якщо об’єкт не належить до потрібного підкласу.
За допомогою ланцюжків цих операцій можна видобути будь-яке Значення будь-якого екземпляру для подальшого використання.
Об’єктні трансакції
Трансакції дуже широко використовується в табличних базах даних, але не стандартизуються засобами SQL - кожна таблична СУБД реалізує їх на свій розсуд. Ми вважаємо, що об’єктна СУБД мусить підтримувати об’єктні трансакції.
Об’єктна трансакція - сукупність послідовних операцій з одним або кількома об’єктами бази даних, яку слід розглядати як атомарну цілісність : або всі операції трансакції є успішними і тоді трансакція в цілому є успішною, або якась операція є невдалою, і тоді всі операції трансакції скасовуються, а база даних повертається у такий стан, неначе трансакція не розпочиналась.
Найпростішим прикладом застосування об’єктної трансакції є реалізація операції зміни значення атрибута. В табличній системі зміна значення поля в одному записі є елементарною операцією, але в об’єктній системі, як ми вже зазначали, це не так. Для зміни значення атрибута треба виконати дві операції : відкрити потрібний об’єкт і потім записати змінений об’єкт в базу даних. Кожна з цих операцій може викликати помилку, тому доцільно об’єднати їх в одну трансакцію. Більше того, для забезпечення стійкого читання (repeatedly reading) необхідно заблокувати цей об’єкт не тільки для запису, але і для читання на весь час трансакції.
Складнішим прикладом застосування трансакцій може бути викреслювання об’єкту з бази даних (для цього спочатку треба анулювати всі посилання на даний об’єкт з боку інших об’єктів, а потім знищити об’єкт).
Блокування, які необхідні для реалізації трансакцій, можна розділити на блокування на рівні екземпляру та блокування на рівні класу. Блокування мусить встановлюватись окремо для кожного методу. Якщо застосування блокування читання та запису на рівні екземпляру є самоочевидними, то блокування запису на рівні класу необхідне, наприклад, під час обчислення середнього значення атрибута для класу, якщо вимагається високий рівень ізоляції трансакцій та, відповідно, висока надійність результатів обчислень. Аналогічно, операція створення нового екземпляру мусить блокуватись під час підрахунку числа екземплярів класу, і т.д.
Можна розрізняти оптимістичну стратегію блокування - вона може вживатись, коли трансакція заздалегідь знає всю множину об’єктів, що будуть охоплені трансакцією. Тоді достатньо заблокувати тільки ці екземпляри (наприклад, під час розглянутої вище операції викреслення). Песимістична стратегія блокування мусить вживатись, якщо трансакція заздалегідь не знає тієї множини об’єктів, яку вона має охопити, скажімо, якщо визначення цієї множини є метою трансакції. Тоді необхідно встановлювати блокування на рівні класів (прикладом може бути застосування методу Вибрати при високих вимогах до ізоляції трансакцій, коли є небажаним, щоб під час вибирання екземпляри додавались або знищувались).